
BigData
分布式系统基础架构,Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
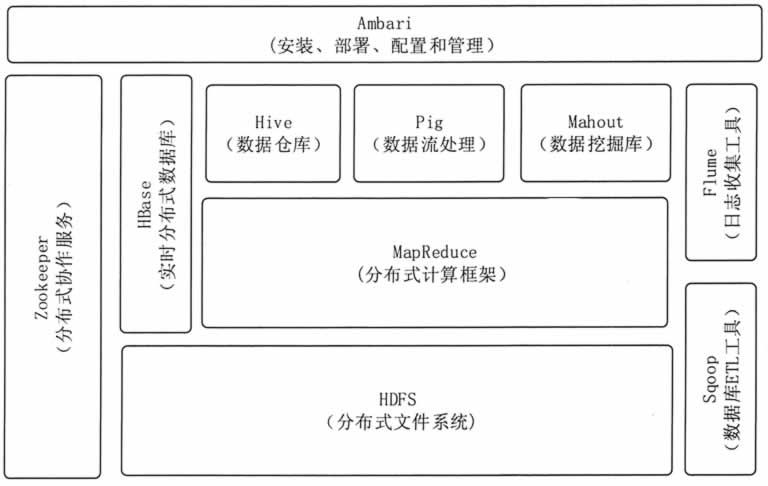
HDFS (存储) 和 MapReduce (计算)
主节点 | 工作节点 | 作业
通用资源管理系统,为上层提供统一的资源管理和调度。
基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)
提取 变形 加载
A high-level data-flow language and execution framework for parallel computation
- 数据仓库工具 ,实现ETL
- 蒋SQL语句转变为MapReduce任务执行
- 数据仓库进行统计分析
- 不适合联机(online)事物处理、不能实时查询
- 最佳使用场合是大数据集的批处理作业,例如,网络日志分析
分布式数据库,面向列的,适用于非结构化数据存储,导入性能只有大约2000条/秒
软件框架
实时版Hadoop,流处理框架,适用:
- 比如网站统计(实时销量、流量统计,如淘宝双11效果图)
- 推荐系统(实时推荐,根据下单或加入购物车推荐相关商品)
- 预警系统
- 金融系统(高频交易、股票)等等
主节点 | 工作节点 | 作业
统一流处理和批处理的框架 一切都是批次
- 大规模数据处理的计算引擎
- 启用了内存分布数据集
- 适用于数据挖掘与机器学习等需要迭代的MapReduce的算法
统一流数据处理与批处理的框架,流处理速度比Storm 快,提供更高级的api,一切都是流
- 批处理和Spark非常相似
- 流处理和Spark不同,和Storm很相似
MPP(大规模并行)分析型数据库产品(亚秒级响应),有效地支持实时数据分析,支持10PB以上的超大数据集
分布式资源管理框架,分布式系统内核
如果把数据中心中的集群资源看做一台服务器,那么Mesos要做的事情,其实就是今天操作系统内核的职责:抽象资源+调度任务
Hadoop YARN、 Apache Mesos 、Kubernetes
Eureka(spring cloud) consule Zookeeper Nacos
CAP理论是分布式架构中重要理论
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)